Investigating Racial Bias in AI-Powered Math Assessments
tl;dr
We investigated potential biases in using large language models (LLMs) to assess math skills in low-income Black and Latine students. We employed 3 primary methods:
- evaluated the polarity in social perceptions of LLM-generated text using the Regard metric
- compared LLM scores to standardized test scores across racial groups
- built and used a bias mitigation framework in a new AI assessment feature with live student users.
While we detected no statistically significant biases in AI-generated assessment scores, we uncovered many unexpected LLM failures that may make models more vulnerable to racial bias. These included sycophancy, prompt sensitivity, and reliability.
From our research, we believe top AI models may pass tests of racism but still bias results against BIPOC and low-income students.
With this knowledge, we've established a framework for testing and mitigating bias when using AI assessments. Using this framework, we launched Progress Reports, AI-powered "forecasts" of student test performance with recommended practice areas.
Introduction
Why AI Assessments?
At UPchieve, our foundation has always been a human approach. Our expert tutors, including many former teachers with extensive education careers, volunteer their time to offer limitless one-on-one tutoring to students in need.
We are committed to maintaining this human element, which has been central to our identity.
We are also aware of the evolving landscape of AI in education, however. Students may now access AI tutors on app stores, and school districts are already mulling over contracts with AI tutor providers! We are also considering how we could apply AI technologies to equitably serve students better.
AI presents a number of opportunities for UPchieve.
Lower costs
AI services, as a complement to human tutors and counselors, could make students, tutors, and UPchieve more efficient:
- Embedded AI tools used during sessions can help students and tutors do more, faster.
- Intake bots, like triage bots in healthcare, can get students set up ahead of a session so tutors can dive right in.
- AI can co-teach with tutors, filling in gaps in the tutor's curriculum or content knowledge.
- AI can redirect tutors and students if they start going down unproductive rabbit holes during a session.
- Standalone AI tutors can handle minor issues, deflecting use of our limited human tutor supply.
By augmenting human tutors with AI, we can provide more targeted, efficient academic support to a greater number of students in need.
Impact measurement
As a direct-to-student non-profit, we lack traditional assessment data useful in impact measurement. Instead, we have a trove of high quality transcripts from thousands of tutoring sessions.
Research suggests oral assessments are effective, especially for struggling students. But they are hard to scale. AI, then, presents an opportunity. Large language models, meanwhile, are capable of holding conversations and at least simulating high-level reasoning. If we are able to use AI to understand student progress and performance, we can use it as a high-fidelity longitudinal impact metric.
Better student outcomes
Furthermore, we expect this understanding of student knowledge to power a plethora of improvements to the current UPchieve service to better serve students. Many students come to us as a last resort, feeling like they are going to fail. To help them earlier in their journey, we need to know where they currently stand. Students often seek this type of feedback from tutors, wondering, "How am I doing? Am I ready?" Assessments would allow us to answer this question for them and provide them recommended next steps.
The Risk of Bias
In all these AI applications, the model must know what students know. It must be able to assess student skill level from observation, like a tutor would. Meanwhile, some research suggests student language can affect human rater evaluations. Given LLMs have learned to "think" based on human writing patterns, would they also be sensitive to student language variations?
We wanted to test this risk before we embarked on AI-powered product features.
Study 1: Evaluating General Bias in Language Models
As an early exploration into this domain, we evaluated racial bias of large language models by replicating a relevant subset of a study done by Hugging Face.
Methods
We used python and the Hugging Face evaluate library to measure bias. We used Regard, which returns the estimated language polarity towards a demographic (e.g. gender, race, sexual orientation). Regard is a measurement that aims to check language polarity towards and social perceptions of a demographic (e.g. gender, race, sexual orientation). It was first proposed in a 2019 paper by Sheng et al as a measure of bias towards a demographic.
We tested against the BOLD dataset. It holds 23,679 text generation prompts useful for checking fairness across multiple domains, including race.
We sampled prompts from the European_American and African_American categories of the BOLD dataset. Then we instructed state-of-the-art (SOTA) models to complete these prompts. At the time of writing, those models were OpenAI's gpt-4-turbo and Anthropic's claude-3-opus.
We looked at how the Regard score differed across the each racial group to assess bias.
Results
The positive score of African_American responses was 5.4% higher. This shows they got more positive regard than the European_American prompts. The negative score difference of -4.8% also suggests models favored African_American over European_American prompts.
This finding contradicts Hugging Face's results on a smaller, older open source model. This makes sense, given the safety measures OpenAI and Anthropic are using before releasing models to the public. We are likely seeing the fruits of bias guardrails provided by private model providers. The BOLD dataset and Regard measure are well-known and often used in academic literature. It is plausible OpenAI and Anthropic have trained their latest models on this data or even optimize the Regard metric.
We found anecdotal support for this idea while conducting the study. First, we could replicate Hugging Face's results when using the small, old, open source GPT-2. Such a finding is of limited practial use, though, as the GPT-2 model is all but obsolete for application uses.
We also stumbled on an intriguing sensitivity when asking the model for help summarizing results. As of this writing, SOTA models will, given the right prompt, display a bias when asked to interpret the results. SOTA models will respond by saying that the data shows a negative bias against African Americans--even when asked to think through the data step by step; even after seeing the raw scores; and even after challenging the model to critique its incorrect interpretation. Perhaps the many other similar interpretations the model has trained on have skewed its responses. Or, perhaps the safety adjustments made by the providers have blinded them to other interpretations.
Note that this bias comes down to sensitivity to the prompt. When we asked the model to roleplay, suggesting they were writing the results to an academic paper, the model misinterpreted the results. When asking it to to interpret the results without context, it interpreted the results correctly.
It is likely a good thing for UPchieve that general purpose use of models appears biased in favor of our largest student demographic. It may be less a good thing if we want to rely on it to assess students, as we must be careful in prompting.
Study 2: Bias in LLM Math Assessments
In the second experiment, we looked at our primary use case: conversational math assessment. Our overarching goal is to understand how these models might discriminate on race. We assume students will speak in sessions with language unique to the racial cultures with which they identify. If so, AI may struggle to assess those linguistic traits or do so unfairly.
We study this hypothesis by:
- collecting a sample of students for whom we have demographic data and standardized test scores
- collecting a sample of their sessions representative of those scores
- prompting language models to grade sessions based on a conversational math assessment protocol and tying the outputted score to the standardized test scale
- analyzing the difference between real scores and AI scores in search for disparity
Data
The demographics, test dates, and test scores came from a past randomized controlled trial (RCT) to measure the effectiveness of UPchieve tutoring at varying dosage. The Gates Foundation sponsored the trial, and Mathematica served as the independent investigator. With standardized scores and demographic information, the data provided the features we needed for this exploratory bias study.
We prepared this data in a CSV prepared in Google Sheets. We then combined these data with UPchieve session transcripts, joined by the students internal UPchieve ID. To do so, we used an extract-transform-load (ETL) pipeline with 'python', 'pandas', and 'jupysql'.
Demographics
During this study, 100 students self-reported demographic information via a survey administered by UPchieve via Google Forms.
We conducted light cleaning of the data, such as casting fields to compatible pandas types. The data included no personally identifiable information (PII) due to prior processing for the RCT.
Race categories include preset options such as "Hispanic or Latine" and "Black" as well as a write-in options. Students could choose as many categories as they wanted. Many students identified with multiple races. We chose to treat each mix of chosen races as a separate category. We believe each unique mix could denote a unique set of cultural norms that may show up in conversation.
Test dates and scores
The same students then completed pre- and post- tests of the STAR Math Enterprise Edition from Renaissance Math before and after engaging in UPchieve tutoring sessions.
The Renaissance STAR Math assessment is a computer-adaptive test that adjusts the difficulty of its questions based on the responses of the student. This approach ensures that the test is challenging for students of all skill levels, providing a more accurate measure of a student's math skill at the time of testing.
These tests use a Unified Scaled Score from 0 to 1400 to represent student performance in the tested area. The Unified Scale Score is ideal because it is independent of grade level or other curve-adjusted measures and can track student performance and growth across time. Having a stable score that proxied students' skills in math allowed us to compare students across grade levels for more statistical power.
Tutoring sessions
The tutoring session transcripts and metadata came from the application data score. We cleaned the data of PII, data errors, and missing values.
Metadata for each session included:
- discipline (Math)
- subject (e.g., Algebra 1)
- concept covered (e.g., solving linear inequalities)
- time of session
- session length
- number of messages exchanged between the student and tutor
- word counts for messages exchanged between the student and tutor
- complete transcripts from the session
We omitted from our final data any sessions that did not meet the following criteria:
- the student reported a race
- in a Math subject
- took place within 7 days of the pre or post test to ensure the knowledge demonstrated by the student in the session still reflected that in the Unified Scaled Score
- the transcript was rich enough to warrant an assessment; i.e., it was at least 15 minutes long with at least 15 messages exchanged and at least 50 words said by the student. The first 2 criteria came from post-hoc analysis of the RCT session data. They are predictive heuristics of a "successful" session, where the student and tutor engaged enough to share understanding and learn a new concept. The latter criteria follows the protocol used by Crossley, et al in 2019.
After omission, we were left with 66 sessions. For each session, we stored the transcript as a string single value, prepending a speaker label before each message in a format familiar to early LLM training data:
Student: Student message
Tutor: Tutor messageGrading
We prototyped a conversational math assessment system in python using pandas and litellm. This system prompted several SOTA language models to simulate an unbiased grading process, provide a rationale much like an oral assessor would, and report a Renaissance STAR Math Unified Scale score.
Models
Though we tested several large language models (LLMs), for the rest of the study we focus only on SOTA models gpt-4-turbo and claude-3-opus. We also attempted similar assessments with smaller models such as gpt-3.5-turbo, claude-3-haiku, and the 70 billion parameter versions of llama-2 and llama-3. We found that the smaller models were incapable of reasoning through the task, though. They often generated the same scoree for everyone and produced unrealistic binomial distributions. As an example, gpt-3.5-turbo rated over 90% of students at either 1400 or 0.
Prompt design
We tried several manually-crafted prompts to guide models in assessing tutoring session transcripts. Each prompt included a detailed description of the STAR Math assessment methods to align the model's grading criteria with those used in the standardized assessments.
The prompt also told the model to follow oral assessment guidelines drawn from practical and academic research to ensure a rigorous assessment protocol. Curiously, we saw the most reliable assessment from the model when we kept our instructions vague regarding conversational or oral assessments. Providing too rigid of instructions caused the model instruction-following to degrade, leading to unparseable response bodies or unrealistic assessments based on relatively unimportant criteria in the instructions. Meanwhile, removing detailed instructions seemed to allow the model to pull from embedded knowledge about the purpose and protocol for conversational assessments, leading to more realistic assessments and better overall instruction-following. There could be many reasons for this behavior, which we leave for future research.
To promote objective assessments, the prompt instructed the models to focus only on math and problem-solving skills in the transcripts. They were to avoid biases related to eloquence or interpersonal skills.
Finally, the prompt required models to respond in XML format with 2 fields for extraction of the LLM response data:
<rationale>
Detailed analysis of the student's ability to learn or apply mathematical concepts to solve problems as evident in the dialogue. `rationale` came first to encourage Chain-of-Thought reasoning.
</rationale>
<score>
a single integer between 0 and 1400
</score>You may find the complete, final prompt in the appendix.
Analysis
To check for bias, we compared mean group differences in AI-assessed and actual scores as our primary metric. We assume that the model may assess students differently on the Unified Scale than a computer-administered adaptive test, but that it should do so indiscriminately. A statistically significant difference across mean group differences would suggest that the model biases scores by race due to varying linguistic traits in the transcripts.
Feature engineering
From each model's session response, we extracted the numerical score and the accompanying rationale. We then took the difference between the student's actual test score and the model's score. Each model's difference served as a new feature in the dataset. Finally, we took an average difference across all models. We assumed the global model average would be insightful because these models use similar training data and technologies. They may thus share a systematic tendency outside each provider's idiosyncratic design choices. In post-hoc review, we noticed that while each model did provide a unique distribution of responses, they also had similar patterns, which could support our assumption.
We then translated all differences in scores positively, ensuring that while the scale remained the same the lowest difference possible was 1. This allowed us to use downstream data transformations that need positive real numbers without affecting the conclusions of the analysis.
Later Shapiro-Wilk tests for normality, a prerequisite assumption for the ANOVA test we used, would reveal a strong left skew in the residuals of the ANOVA. We applied the Box-Cox transformation on the score differences because it had the best results normalizing the data. Log, inverse, and other transformations failed to normalize the residuals. Note that only the Box-Cox transformed score differences for claude-3-opus failed to reject the null hypothesis of the Shapiro-Wilk test. The results from the following parametric tests are robust only for this one model, but this was enough for our analysis.
Statistical tests
We used a one-way ANOVA to determine if there were statistically significant differences in the transformed scores across different racial groups. ANOVA allows for comparing means across many groups, which fits our analysis involving many racial categories.
Given the many comparisons involved in our analysis, we conducted post-hoc testing using Tukey's Honestly Significant Difference (HSD) test. This test allows us to see which specific pairs of racial groups showed significant differences in scores following the ANOVA. Using Tukey HSD for this purpose helps control for type I error that occurs when conducting several pairwise tests.
Results
We found trends in the effect sizes across models but no statistically significant differences. With the caveat that the range of the 95% confience interval for possible population averages remains very wide, we noticed each SOTA model shared a similar pattern for central tendencies.
- White and Black students had similar averages.
- Hispanic and Latine students had an average roughly 7% lower than that for White students.
- Students who identified as both Black and Hispanic or Latine had the lowest averages relative to White students of the 3 groups, with an average roughly 15% lower than that for White students
- The average for Asian students was the worst relative to that of White students. This pattern most strongly persisted across all SOTA models.
We describe the results for each model below.
GPT-4 Turbo
The ANOVA results showed no significant differences in scores across racial groups (F(4, 41) = 0.288, p = 0.883). The Tukey HSD results further supported this, showing no significant differences between groups. All comparisons had p-values well above 0.05. Recall, however, that these results are largely inspirational in nature, as the shape of the residuals did not abide by the assumption of normality required in these tests.
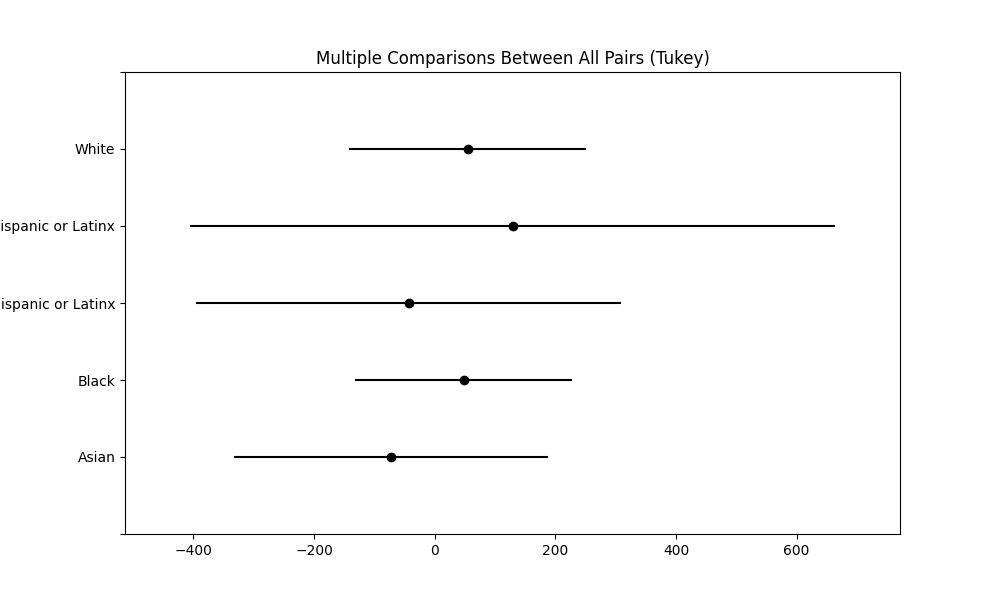
Claude 3 Opus
The ANOVA for this model also indicated no significant differences in scores across racial groups (F(4, 40) = 0.773, p = 0.549). The Tukey HSD test confirmed the lack of significant pairwise difference.
Average of all models
When considering the average scores across all models, the Shapiro-Wilk test statistic was 0.923 with a p-value of 0.0047, indicating slight non-normality. The ANOVA results reflected no significant differences in the average AI-assessed scores across racial groups (F(4, 41) = 0.439, p = 0.779). The Tukey HSD test mirrored these findings, with no significant differences found between any racial groups.
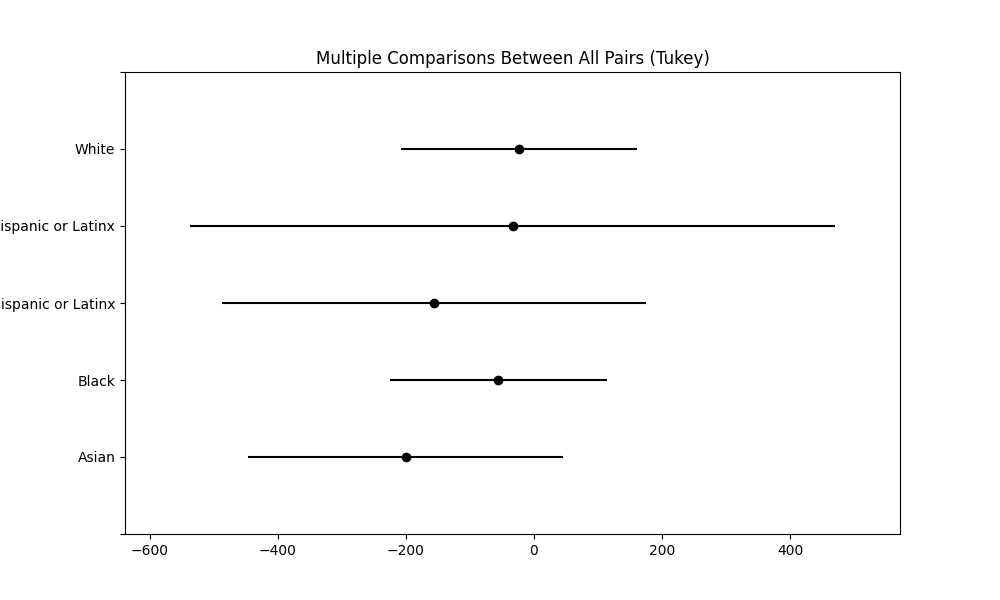
Conclusions
Our statistical tests suggest AI models do not bias scores across different racial groups. That is promising, as it suggests we could deploy an AI-automated assessment without substantical concerns for racial equity.
In practice, however, we ran into unexpected failure modes of SOTA LLMs that may highlight potential risks for bias. Take, for example, the following case study: the total failure of our attempt to use synthetic twins for testing bias. For this research, we originally planned to translate English transcripts into African American Vernacular English (AAVE) and Mexican Spanglish. We would do this to test if language models biased scores against these synthetic twins. Unfortunately, the models failed to perform these translations at all. They often reverted to conventional Spanish translation or outdated and stereotypical AAVE representations. Despite attempts at prompt tuning to yield a different result, we could not get a synthetic twin we felt represented these dialects. This failure could show a profound limit in the models' ability to understand and represent these languages and cultures.
We discuss more practical considerations in the next section.
Practical Challenges and Considerations
Our experimental results show little racial bias. Anecdotally, however, we discovered many practical issues that may bias AI assessments for our students.
"Sneaky" Bias
Several unexpected failure modes, while rarely associated with fairness research, could make models vulnerable to bias in subtle ways.
Sycophancy
The models in our study suffered from sycophancy, which is the tendency for AI to take on the same opinion shared by the user. We manually reviewed transcripts and the rationales the model used to assign scores. There we found that models tended to believe students who say they are bad at math--regardless of whether they are.
This behavior could affect certain cultural groups that practice more humility or self-effacement, such as some Asian cultures. In Study 2, we saw a large (though statistically insignificant) gap between actual and assessed scores for students who identified as Asian. If we were able to confirm this finding in future experimental results, one explanataion could be cultural norms of modesty and self-criticism.
Steerability
Steerability refers to the models' sensitive to the specific phrasing of prompts. We struggled to steer SOTA language models, which can simultaneously be too steerable and not steerable enough.
The models were often sensitive to prompts:
- the case from Study 1, where the prompt for interpreting the results could yield completely opposite conclusions from the model.
- when explaining the oral math assessment protocol, contrary to common advice, prompts that were specific often led to poorer performance compared to more vague ones.
- the content in the examples used in few-shot prompting techniques affected the kinds of concepts the model looked for when assessing the same transcripts.
Such sensitivity raises concerns. After all, depsite best of intentions, bias may sneak in by the individuals crafting these prompts if the prompts reflect the unconscious biases or assumptions of their developers or users. Furthermore, some research has suggested traditional assessments often have their own disparate impacts due to implicitly biased test design. Such steerability also poses the risk that any traditional assessment translated into AI instructions may pass on the same inequities.
Yet, depending on the rest of the context provided with the instructions in the prompt, the same models may also be unreliable. In Study 2, the model seemed to favor the most visible components of a tutoring session transcript, even if they were not related to math skills. For example, despite explicit instructions to avoid testing students on non-math concepts, model rationales would often still analyze skills like "professionalism," "engagement," "learning," or "communication." We leave the confirmation and explanation of models' tendency to attend to the most visible components of the transcript to future research. If confirmed however, this would raise equity concerns. Different cultures value and express these soft skills uniquely, so any assessment based on values outside those cultures risks introducing bias.
General Inaccuracy
Our study also showed general inaccuracies in model performance. These may not "sneak in" bias but could impact the reliability of these models for educational assessments.
Regression to the mean
The distribution of scores provided by AI clustered around the mean more than actual scores. Even the many outliers clustered into what appeared a multi-modal distribution that would decompose into tight distributions. This could show a regression to the mean in model predictions, a documented phenomenon in AI models. If so, models may fail to differentiate between fine grains of student performance or may fail to spot outliers at all.
Overpositivity
Models tended to be too positive, failing to critically assess students, even when instructed to do so. This was particularly evident with the GPT-4 Turbo model, which displayed a stark contrast to the slightly more balanced assessments provided by Claude 3 Opus. This could be due to the instruction fine-tuning processes the model providers go through, given their incentives to provide a good user experience.
Stochasticity
Finally, we observed that the response to the same prompt for the same session could still lead to different scores when repeated. The non-deterministic nature of AI models complicates the use of these models for consistent educational assessments. This inconsistency could be particularly problematic in high-stakes testing.
Conclusions
Our anecdotal evidence does not prove AI models are biased. We hope, however, that these cases inspire more research and a skeptical, critical, and broad approach to reducing bias when deploying these models for public use. The unexpected challenges we encountered highlight the complexity of using AI in educational settings. It is not just about explicit racism. Many common issues with general-purpose SOTA LLMs also make it challenging to build fair and accurate AI assessment tools.
Bias mitigation framework and its practical application
Bias mitigations
Our findings had limited statistical power but provided a valuable framework for testing and reducing bias in AI-powered assessments. We compiled a set of research-backed (and often simple) bias mitigations to install when using AI for student assessment. These mitigations address both "sneaky" vulnerabilities to bias and general inaccuracies in assessment:
- Instruct the model explicitly not to exhibit bias.
- Use prompt optimization tools to avoid implicitly introducing bias. In theory, these can convert the task of prompt engineering into an optimization problem, where an ideal prompt evolves to perform best on a racial equity metric.
- Use a critic model, the same or another high-performing model instructed identify and correct potential biases in assessments.
- Use grounding techniques to constrain the concepts the model assesses to those we care about and away from the more visible but subjective measures
- Use decomposition: break down the task into smaller, more objective outputs, and then ask the model to derive a final score from these components (e.g., "(1) What kind of problem is the student working on? (2) What are the skills required to solve such a problem? (3) What evidence would you likely see in a conversation if a student had these skills? (4) Does the student exhibit the following behavior?")
- Use a rubric (a special case of grounding or decomposition)
- Provide diverse (even synthetic) examples
- Use ensemble methods on variable score outputs, while monitoring the intra-reliability of the model scores to provide more robust final scores
Progress Reports: fair assessments in practice
We used this framework to release Progress Reports, our first AI-powered assessment feature. Progress Reports assesses student abilities to "forecast" how well they will do on upcoming class assignments, assuming tutoring comes before class tests. With Progress Reports, students complete tutoring sessions as usual. Afterward, we rate their performance in the session then provide students recommended practice areas to focus on in their next UPchieve session.
With a set of mitigations in place, our main questions for Progress Reports have shifted from equity to impact. Do students engage with it? Do they enjoy it? Do they find it useful? Is it driving higher student performance? Early signs have pointed to yes.
But we also hope to further support our bias research through Progress Report use. As part of the experience, students can leave feedback on the accuracy of the forecasts and report actuals. We hope to recruit a new set of users to provide demographic information and standardized test scores. By doing so as scale, we can build a much larger sample for future studies like the research done here.
Future work
As we roll out Progress Reports to all our students, we will need to solve some of the remaining challenges we encountered deploying AI in production. For example, assessments in this study did not incorporate the outputs of vision models. Current models struggle to interpret the complex interactions represented on our virtual whiteboards. With the rapid pace of innovation in prompting and models, however, we expect this data should lead to more accurate assessments soon. It also has the potential to surface potential biases, if students who identify with different races use the board in different ways, or subdue said baises, if not.
The best way to track bias on an ongoing, operational basis remains an open question. Benchmarks for racial bias and each of the identified vulnerabilities do indeed exist, but no production system incorporates them all. Additionally, the rapid advancement of AI technology means our benchmarks may become outdated. Staying abreast of the latest developments in AI benchmarks, especially as we encounter new failure modes not yet discovered, will be necessary, ongoing challenge.
The AI tooling landscape is improving, but it is still nascent. We expect better, more reliable tools for bias assessment and mitigation to emerge. These tools will make it easier to ensure fairness in our AI-powered assessments.
Despite these challenges, we are excited about the potential of Progress Reports to help students learn more, faster, regardless of how they express their racial identity.
Limitations and future research
It's important to acknowledge the significant caveats and limitations of this study. Given these limitations, we encourage readers to view the results as indicative and inspirational rather than definitive. This study is an exploratory proof of concept that highlights areas for further, more rigorous research.
We assume race is a stand-in for culture and that students reflect that culture in the sessions. We have anecdotally observed of this behavior while monitoring student sessions, which inspired the study in the first place. Manual reviews of the test data also confirmed language differences among students who identified with different races. Nonetheless, it may not always be the case or even common within the broader population.
With manually crafted prompts like those of this study, the effectiveness of the chosen prompts varies with the time invested and skill of the researchers. It is possible better prompts may have yielded different results.
We also make a number of assumptions about the relevance of scores from the model in predicting standardized test scores. First, we assume that oral or conversational assessments are good predictors of the normalized Unified Scale Score of the STAR Math standardized test. Some research has pointed to the validity of oral assessments scores compared to traditional exams, and for this reason they are sometimes used to "level the playing field" for students with disabilities during high-stakes standardized testing. Meanwhile, other research has suggested oral and traditional assessments test different skills, reporting a medium to strong correlation between oral assessment scores and final exam scores. Even if the model's oral assessments were to highly correlate with these test scores, the tutoring sessions may surface only a few of concepts covered by the a traditional standardized test. The model may then generalize incorrectly. For example, students are likely to come to us with their weakest concepts, so AI assessments may score students too low relative to a comprehensive assessment. (Note that, likely due to biases introduced in AI training, we actually saw the opposite problem in our study.) Finally, some sessions may not have rich or relevant enough interactions between the student and the tutor to provide the model the evidence required to make any assessment, and the model may simply hallucinate. We took steps to remove sessions like these, but the risk remains.
Third, the analysis of sessions is likely looking at only part of the evidence students provided of their understanding. Evidence of student content knowledge in online UPchieve sessions is likely to be multimodal, but at the time of this study we lacked access to important data like digital whiteboard changes and event timelines, so the models looked at conversation transcripts only.
As a small-scale proof of concept rather than a rigorous experiment, the study also lacks robust controls. Students varied in location, gender, school, and grade level, and the cases and concepts covered in sessions were manifold. Tutor quality ranged from poor to excellent, and student engagement levels varied both within and across sessions. We had intended to conduct a matched-pairs experimental design using propensity score matching, but with only 66 samples, we lacked enough data to control for all variables. We considered matching based on similar transcript embeddings as an alternative, but we realized that the embedding itself could be biased and corrupt the analysis.
Future research
Future studies might explore statistical approaches that are robust to deviations from normality. Given the already limited statistical power and the likelihood that non-parametric tests would be less powerful, we did not yet embark on this.
It's also worth noting that our study used conventional hypothesis testing methods, where the burden of proof is on showing there is a difference between racial groups. But other research suggests that AI models do indeed show bias. As such, an alternative approach could be to start with the theory that the model scores are different across racial groups, and the burden of proof would be to show that they are the same. This approach would need methods such as Bayesian tests or Two One-Sided Tests (TOST) on the same data, although it may also need more data or a well-informed prior.
We may also revisit the prompt design. For example, why did removing explicit oral assesment protocol instructions improvement model instruction-following? One theory could be that including the instructions increased the size of the input context, which tends to reduce performance on models, even those with long context windows. Future research could prioritize different components of the prompt for inclusion within the context, evaluate models on a more complex "needle in a haystack" text based on the use case here, or use the same prompt optimization tooling used in our bias mitigation framework as an attempt to control for these issues.
We could also tailor future Regard assessments to custom datasets. These should better represent our task and the context of AI-powered math assessments in tutoring. For example, we could try to simplify the abandoned "synthetic twin" test by appending the student's race to the session transcripts. Or, we could synthesize a new dataset like the BOLD dataset but based on tutoring session interactions, where we ask for completions of tutor responses. Given the safeguards model providers have put in place, we doubt either of these tests will contradict the Regard results we found in Study 1. But it could better confirm that we can trust AI to know what students know.
Conclusion
Despite the limitations, our work laid the groundwork for both fairness research and practical deployments of AI assessments at UPchieve. Our tests did not show bias in the AI scores across racial groups. But, we found "sneaky" vulnerabilities for bias. These include the models' tendency to be sycophantic, their high sensitivity to prompt wording, and their habit of assessing subjective skills even when told not to. We used research-based methods to cut out risks of bias, which let us launch Progress Reports with confidence.
We hope our work inspires other education researchers and edtech providers to do better bias research or put in place even more effective mitigation strategies than we did. If more organizations advance fairness in AI education, AI tools will better serve all students, including--especially--the kids we serve at UPchieve.